For better or worse, most of the software I write I can’t make publicly available. If I can share a repo here below but it needs to be restricted (say to Stanford employees only), I’ll note that after the name. Some things I can only make available to my current team as of now, but I’ll work to change that. If you want some specific examples, I can probably provide something by request.
Infrastructure
I build and maintain a lot of cloud infrastructure, primarily with terraform but scripting too. Much of this centers around kubernetes deployments (in EKS and GKE), so I’ve done many projects with vanilla manifests, helm, and kustomize. I’ve been or am a code owner for both infras-wide terraform and service family kustomize setups. This get big and are super private.
trino-kustomize and trino-terraform: kustomize and terraform setups for deploying a (vanilla) trino cluster. These aren’t super developed, but are the basic skeleton for a proprietary deployment I have actually used.
golang
envoy-extproc-sdk: I got pretty psyched about envoy’s external processor functionality recently. I have a python implementation of some boilerplate to make using tis kind of edge function easy, but also have felt for a while I should learn more about go. So I’ve been using this real-world use case as a way to get more into go.
efnlp: There’s also some go code in a project related to (large) language modeling. This is largely to facilitate efficient “model” serving. I would use this code in Apache Beam / GCP Dataflow too, but the go tooling isn’t quite prime time yet (doesn’t seem to effectively parallelize large scale BigQuery reads).
rust
efnlp: I’m starting to learn rust via a pet project related to (large) language modeling. I’m particularly interested in pyo3, which looks like a super clean interface to enable use of safe and performant compiled code in python. In this project rust basically makes “large” scale analysis (e.g., english wikipedia, openwebtext) feasible; pure python just doesn’t cut it.
python
Oh boy there is alot of python. But most of it is specific to certain research projects or other endeavors, and probably not worth sharing outside of specific circumstances. See, for example, my code used for assisting with Glenn Carroll’s “Authentic Distilleries” studies (an implementation of the ideas discussed next). I actually use python pretty much every single day at work with tools like Flask, FastAPI, numpy/pandas, kafka etc, but most/all those projects are proprietary.
apache-beam: I’ve got (to date) one Apache contribution! Of course it’s tiny. But yet, I needed it to analyze text data in dataflow.
envoy-extproc-sdk: I got pretty psyched about envoy’s external processor functionality recently. This is a python implementation of some boilerplate to make using this kind of edge function easy. Two useful features are (a) cross-request-phase context data and (b) pythonic decorator-style request phase handler declaration. This is in principal a pretty powerful toolkit for passing off boilerplate-but-idiosyncratic API logic from the application to the edge. For example, there are applications in request/response validation, idemopotency handling, data security, and probably more.
bneqpri: Implementation of a fixed point method (from my academic work) for computing Bertrand-Nash Equilibrium Prices (“BNEQPRI”) with a mixture (i.e., integral) model of customer demand for products. Object-Oriented for convenience with extensible importable base classes, but also a CLI if you provide the files. I play with this every now and then, but honestly it’s just for fun.
kalman filters: Straightforward implementation of Kalman Filter logic for GPS data on top of pandas and numpy. Yes, I know there is pykalman, but there’s a library for everything. This was a useful naive example to get some basic results for.
idlogit (in progress?): A python package for estimating (binary outcome) “Idiosyncratic Deviations Logit” models using ECOS. idLogit models are Logit models for heterogeneous observations with a non-parametric portrait of response heterogeneity and a convex maximum likelihood estimation problem. You can review the slides for an academic talk at Stanford’s ICME about this method here.
comparing discrete choice models: A related application I can release is a simple(-ish) notebook-python example for, well, comparing discrete choice models. The main notebook itself probably speaks for itself, but the main idea is to discuss alternative “Logit-like” discrete choice models.
blendnpik: Allright, this one is tiny. But it’s still an example. A while ago I got pretty interested in learning more about randomized methods for solving linear systems. I’ve let this thread of interest die off, and should probably pick it up again. In any case, I wrote a simple, single-file implementation of the blendnpik method in python for learning purposes.
Serverless Codes: I’ve written a number of serverless functions using python. Some are for fun; for example, we have a few Slack apps that call python Lambdas to transform or manipulate text, such as converting a string to binary:

A more useful example comes from our monitoring systems. We have a Slack app built on top of a Lambda that allows us to access summary metrics data about our machines; for example,
/yen 3 publish
displays
![]()
for the entire channel to see and
/yen 3 users publish
displays

for the entire channel to see. Actually, this user-specific data comes from a Lambda pipeline too: code on the actual servers sends process data to S3, and a python Lambda executes a rollup operation on the data to get and store user statistics.
I’ve also helped teams set up complicated serverless applications, including Machine Learning model evaluations in python (with both Lambda using Layers and Google Cloud Functions), code for which I can discuss but can’t share.
javascript
wrossmorrowart: Obviously I’m doing all the coding related to my art site. I’m trying to keep this super slim and low key, so it’s all old-school scripts.js style not fancy modern node.js/react/next style.
Coordinator: A DAG-like asynchronous operation processor for node.js for when you need sequences of operations to either all succeed or fail if any fails. Easily add operational “stages”, with or without prerequisites, rollback rules, and result transformations. Allows repeated executions, as many times as needed, even with new “data” (but not a new execution graph). Published as daat-coordinator on npm, where “DAAT” stands for “Directed Acyclic Asynchronous Task”. Current code is callback based; I’ll make a promise-based version soon I promise.
statesampler: A simple node.js server for state-dependent sampling of data for custom javascript surveys, such as in Qualtrics. For when you need to sample data for custom questions, but your sampling strategy is not iid but rather Markov or something similar. Repo includes a node.js server and systemd service setup. This tool has been used in several experiments at Stanford at this point, involving many thousands of experimental observations, without issue. Through this, I have been able to use real-world experimental data to show that properly (and simply) randomized sampling achieves nearly-optimal distributional performance for experimental tasks in the presence of participant dropout; better performance that that achievable with a priori experimental plans, even when accounting for dropout.

Contact me if you want to chat about this.
yenaccess (Stanford only): A full-stack javascript project (mongoDB, node.js, and react/redux) for managing sponsored access to Stanford GSB’s “yen” research computing servers. This project completely automated a manual workflow our team was responsible for, brought us into compliance with system security auditing requirements, and has been in use for over a year (5 academic quarters). A node.js backend serves an API accessible from a react/redux SPA that furnishes a request form, approval/rejection/renewal forms, and an administration form for tool admins. The project logs all requests for access and request activity, sends notifications and reminders via email and Slack messages, automatically expires requests that get too old, and automatically notifies sponsors of possible renewals (on a timeline consistent with Stanford ISO minimum security guidelines).
cloudforest (public release in progress, successfully in production at Stanford GSB for over a year): A full-stack javascript project (mongoDB, node.js, and react/redux) for managed on-demand AWS EC2 cloud computing services. Also includes monitoring and automation via influxdata‘s TICK stack.
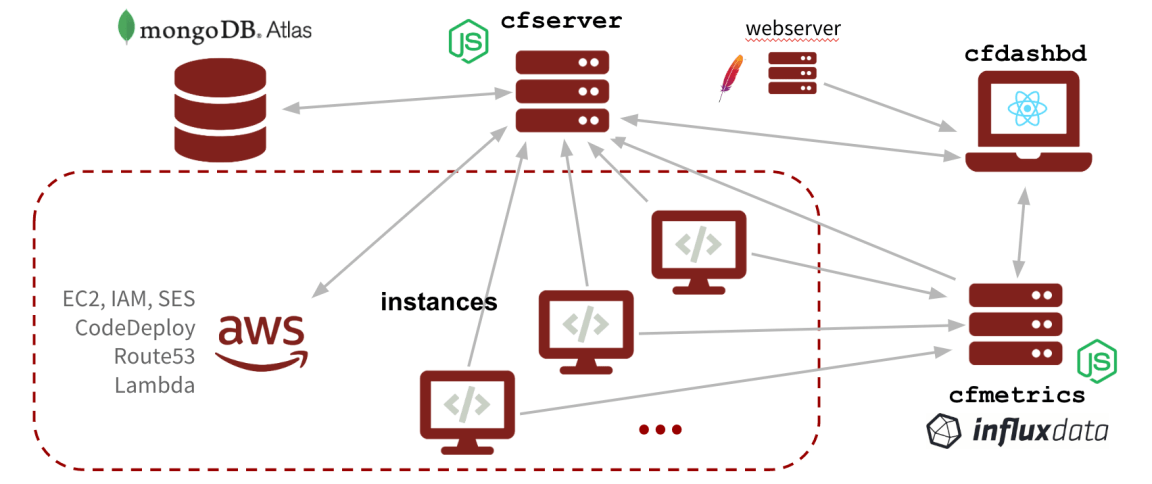
Currently in use at Stanford GSB to enable self-service, efficient, and secure cloud computing for research purposes. Our installation has managed about $70k worth of computing resources in a year of platform use.
cfserver (Team only): a node.js server that interacts with mongoDB and AWS, providing the basic infrastructure for on-demand cloud computing.
cfmetrics (Team only): a node.js server that provides and interface to the TICK stack for instance monitoring.
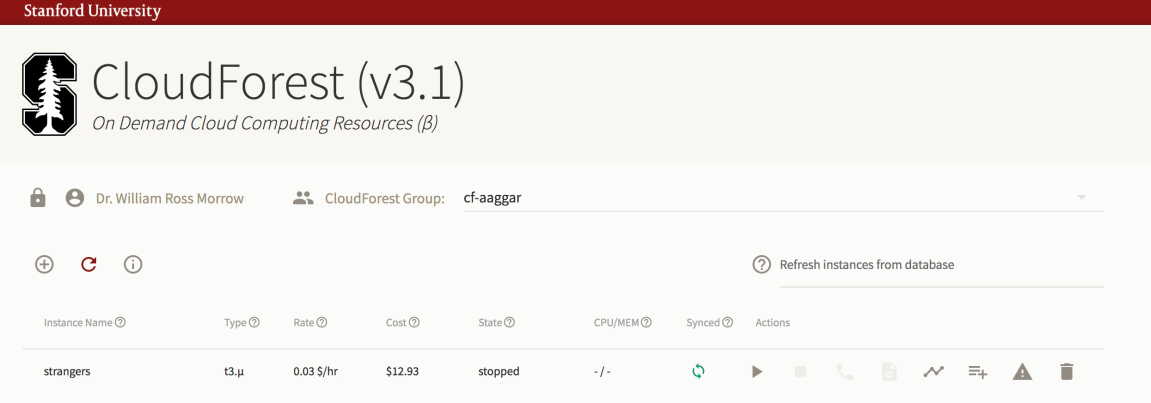
cfdashbd (Team only): a react/redux app providing dashboard functionality for cloudforest including instance management (creation, starting/stopping, deletion), activity monitoring (CPU/memory usage), group management (viewing, adding, removing users), access to jupyter notebooks, and more:
cfsetup (Team only): a structured repository of bash scripts defining how to set instances up after they launch. Uses bitbucket pipelines and AWS CodeDeploy to consistently deploy updates to instances.
cfsite (Team only): repo for a jekyll site, with build and deploy pipelines, containing basic information about cloudforest, complete documentation, and articles about use of the platform.
bash
Like python, there’s alot of (mostly) case-specific bash programming in my life. I’ve written a variety of simple “wrapper” utilities to make certain low-level functionality more accessible to users of GSB research computing systems, such as running (embarassingly parallel) jobs in parallel, or to watch (otherwise unconstrained) resource consumption on our interactive machines. I can share a couple of silly, but maybe still demonstrative, examples.
superserver: A bash script (basically) that can help load balance horizontally-scaled arbitrary servers (like from python, node.js, or go code). You specify the source, start/stop actions, and any install commands, superserver sets up all the (restarting) systemd services for you to run an arbitrary number of instances of your server load balanced by your Apache web server.
stanshib (Stanford only): A set of scripts and templates for making Stanford Shibboleth setup easy on new machines/addresses.
FORTRAN/C/C++
pthreader: A lightweight C++ class for executing arbitrary code in parallel using pthreads, requiring only a definition of (a) setup, (b) evaluation, and (c) cleanup for each thread. Setup and cleanup once, but evaluate as many times as needed. Extends the condition variable mutual exclusion method from Divakar Viswanath’s book.
gslregressmpi: A simple example in C I wrote for a GSB professor interested in using MPI on our clusters to parallel function/derivative calls when solving an optimization problem. This example used OLS regression because it is trivial to implement other ways and verify results. Their real problem was much more complex, of course. This example also uses the GNU Scientific Libraries because this was the faculty’s preferred solver. The basic outline should work with any similar solver.
Price Equilibria: All the code for the work described in this paper was done in C. I should dig it up and post it here.
Code Optimization: I do a decent amount of low-level code optimization when people need it, but most of these cases are particular to a particular researcher and project and not shareable. In one particularly tangible case, I re-wrote some FORTRAN code multithreaded using OpenMP to simpler, optimized serial code which took a 35-day multi-task runtime down to 1 1/2 days. In another, I optimized and rewrote matlab scripts both in matlab and in C using the Intel IPP and MKL, improving speed by a factor of 5. This is a pretty small gain, actually, and is small due to the density of linear algebraic operations in the original matlab code (operations which matlab inherently does well already). Another case involved data extraction from ~ 50GB of detailed XML datafiles from a financial firm; using the Xerces library in C++ was able to tackle the task easily in an afternoon, whereas (naively) trying the same task with python (for fun) crashed a 32-core, 256GB memory AWS EC2 instance.
MATLAB
I used to do quite a bit of MATLAB programming. Sometimes I still help people using matlab optimize their code, but mostly I don’t use it anymore. Here are some examples though.
gmmlogit: These are codes for doing “Generalized Method of Moments” estimation of Logit models. Mostly this was for learning about the “constrained OLS” style formulation of Dube, Fox, and Su.
Smart Parallelism: I used MATLAB for this simple case study of how to (not) run things in parallel on our shared research computing servers (or your own, for that matter). We have a persistent issue of users parallelizing work that is already implicitly parallelized by their software, and thus creating counterproductive amounts of CPU contention. MATLAB was a good environment for this sort of case study because (1) it’s a CPU hog by default, (2) changing how many cores it tries to use is easy, (3) “expensive” operations like solving linear systems can be trivially written in the syntax, and (4) I don’t know other, more GSB-popular platforms with the same problem (e.g., Stata).
Price Equilibria: All the code for the work described in this paper was done in MATLAB. I should dig it up and post it here.
